10 tools to parse information from web sites, including the prices of competitors + legal assessment for Russia

Tools web scraping (parsing) is designed to extract, collect any public information from web sites. These resources are needed when you want to quickly receive and store in a structured way any information from the Internet. Parsing websites is a new input method that does not require re-entering or copypasted content.
This kind of software searches for information under the user's control or automatically, selecting new or updated data and storing it in such a way that the user has quick access to them. For example, by using parsing to gather information about products and their pricing on the Amazon website. Below we will examine the use of web tools, data extraction, and the top ten services that will help to gather information without writing special code. Parsing tools can be used for different purposes and in different scenarios, consider the most common use cases, which can come in handy. And give a legal assessment of the parsing in Russia.
1. Data collection for market research
Web services retrieve the data will help to monitor the situation in the direction that you will seek a company or industry in the next six months, providing a strong Foundation for market research. Software parsing is able to receive data from multiple providers, specializing in data Analytics and research firms of the market, and then to bring this information in one place for reference and analysis.
2. Retrieving contact information
Parsing tools can be used to collect and organize data such as postal addresses, contact information from various websites and social networks. This allows you to make convenient lists of contacts and all related business information – data about customers, suppliers or the manufacturers.
3. Solution to load with StackOverflow
With the tools of parsing of sites you can create a solution for offline use and storage, collecting data from a large number of web resources (including StackOverflow). Thus it is possible to avoid depending on active Internet connections, as data will be available regardless of whether there is an opportunity to connect to the Internet.
4. Job search or employees
For the employer who is actively seeking candidates to work in their company, or for a candidate who is looking for a certain position, tools of parsing will also become indispensable, with their help you can customize the sample data based on various filters attached and effectively obtain information, without completing the search.
5. Tracking prices in different stores
These services are useful for those who actively use the services of online shopping, track prices on products, looking for things in several stores at once.
In the review below did not get the Russian service of parsing of sites and the subsequent monitoring of prices XMLDATAFEED (xmldatafeed.com), which was developed in Saint-Petersburg and mainly focused on the collection of prices in the subsequent analysis. The main objective is to create a system of decision support for managing pricing based on open data competition. Of curious it is necessary to highlight the publication of data for parsing in real time :)

the
10 best web tools for data collection:
Let's consider 10 of the best available parsing tools. Some are free, some give free trial for a limited time, some offer different tariff plans.
1. Import.io
Import.io offers the developer easy create their own packets of data: it is only necessary to import the information from a particular web page and export it to CSV. You can retrieve thousands of web pages in minutes, without writing a single line of code, and create thousands of API according to your requirements.
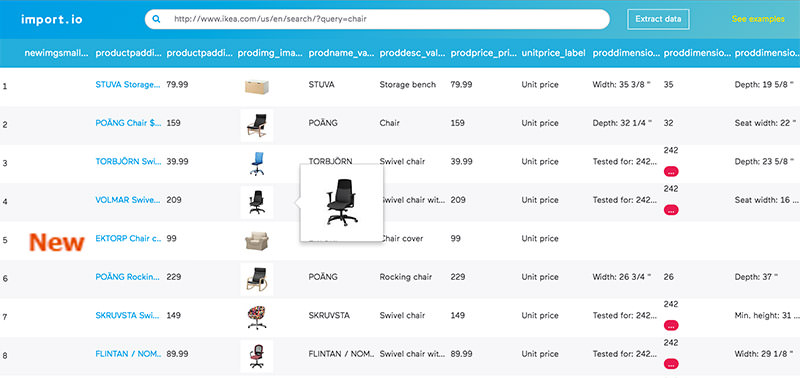
To collect huge quantities of the desired user information, the service uses the latest technology, and low price. Together with the web tool is available as free app for Windows, Mac OS X and Linux to create data extractors and search engines, which will provide data download and synchronization with an online account.
2. Webhose.io
Webhose.io provides direct access in real time to structured data received as a result of parsing thousands of online sources. This parser is able to collect web content into more than 240 languages and save the results in various formats, including XML, JSON and RSS.

Webhose.io is a web app for the browser that uses its own technology of data parsing that allows you to process huge amounts of information from multiple sources with a single API. Webhose offers a free plan for handling 1000 enquiries per month and $ 50 for the premium plan, covering 5,000 queries per month.
3. Dexi.io (formerly CloudScrape)
CloudScrape able to parse information from any web site and does not require download of additional applications, as Webhose. The editor sets itself to your search engines and retrieves data in real-time. The user can save the collected data in the cloud, like Google Drive and Box.net or export data in CSV or JSON.
CloudScrape also provides anonymous access to the data, offering a number of proxy servers that help to hide the identity of the user. CloudScrape stores data on their servers for 2 weeks, and then their archives. The service offers 20 hours free, after which it will cost $ 29 per month.
4. Scrapinghub
Scrapinghub is a cloud – based tool for parsing data which help to choose and collect the necessary data for any purpose. Scrapinghub is using Crawlera, a smart proxy rotator, equipped with mechanisms able to bypass the bot protection. The service is able to cope with the huge amount of information and are protected from robot sites.

Scrapinghub converts web pages into an organized content. The team provides an individual approach to customers and promises to develop a solution for any unique occasion. The basic free package gives access to one search robot (handling of up to 1 GB of data,$ 9 per month), the premium package provides four parallel search engine bots.
5. ParseHub
ParseHub can parse one or many sites with JavaScript, AJAX, sessions, cookies and redirects. The app uses a technology of self and is able to recognize the most complex documents in the network, then generates the output file in the format needed by the user.

ParseHub is separate from the web application as a desktop program for Windows, Mac OS X and Linux. The program provides free trial five search projects. The tariff of the Premium plan for $ 89 involves 20 projects and processing 10 thousand web pages for the project.
6. VisualScraper
VisualScraper is another one to parse large amounts of information from the network. VisualScraper retrieves data from multiple web pages and synthesizes the results in real time. In addition, the data can be exported in formats CSV, XML, JSON and SQL.
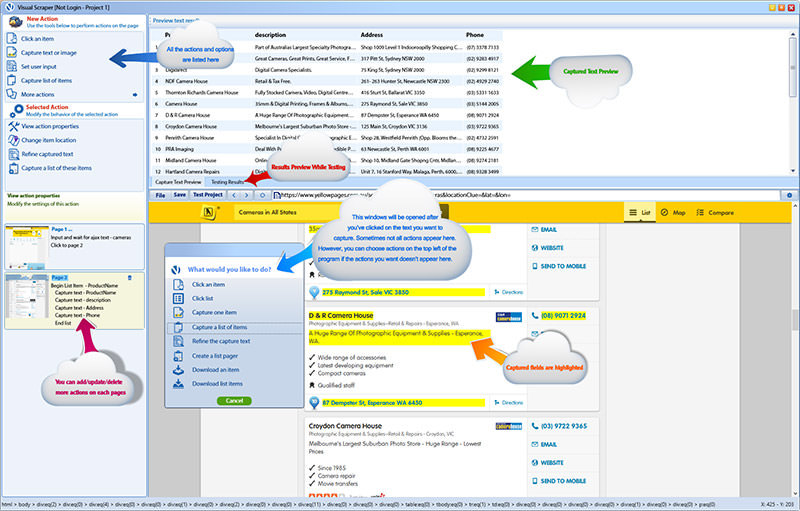
To use and manage web data helps the simple interface point and click. VisualScraper proposes a package with treatment of more than 100 thousand pages with a minimum cost of $ 49 per month. There is a free app that is similar to Parsehub available for Windows with the ability to use extra features.
7. Spinn3r
Spinn3r allows you to parse data from blogs, news feeds, news RSS and Atom feeds, social networks. Spinn3r has the "updated" API, which makes 95 per cent of the indexation. This implies improved spam protection and an increased level of data security.
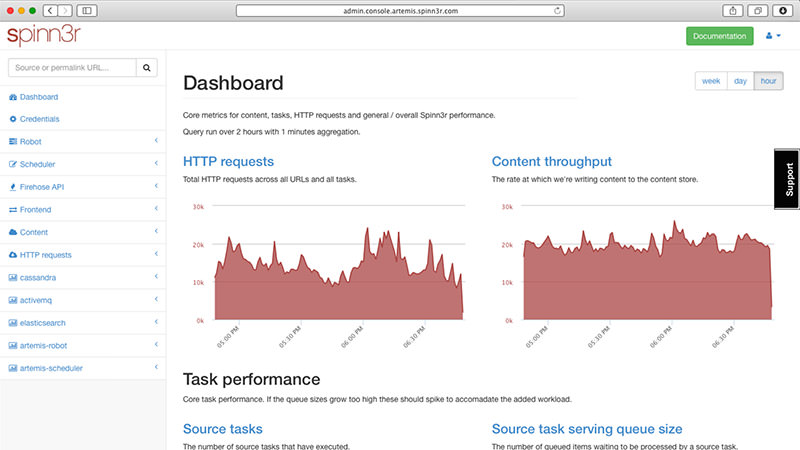
Spinn3r indexes your content, as Google, and saves the extracted data in files in JSON format. Tool constantly scans the network and finds the updates you need information from multiple sources, the user has real-time updated information. The administration console allows to manage the process of research; a full text search.
8. 80legs
80legs is a powerful and flexible web tool parsing of sites, which can be very precisely adjusted to the needs of the user. The service copes with amazingly huge amounts of data and has the function of immediate retrieval. 80legs customers are giants such as MailChimp and PayPal.

Option "Datafiniti" allows you to find data super-fast. Thanks to her, 80legs provides highly effective search network, which selects the necessary data in seconds. The service offers free package – 10 thousand links per session, which you can upgrade to the INTRO package for $ 29 per month – 100 thousand URLS per session.
9. Scraper
Scraper is an extension for Chrome with the limited functionality of parsing the data, but it is useful for online research and export data into Google Spreadsheets. This tool is intended both for beginners and for experts, who can easily copy data to the clipboard or storage in the form of spreadsheets using OAuth.
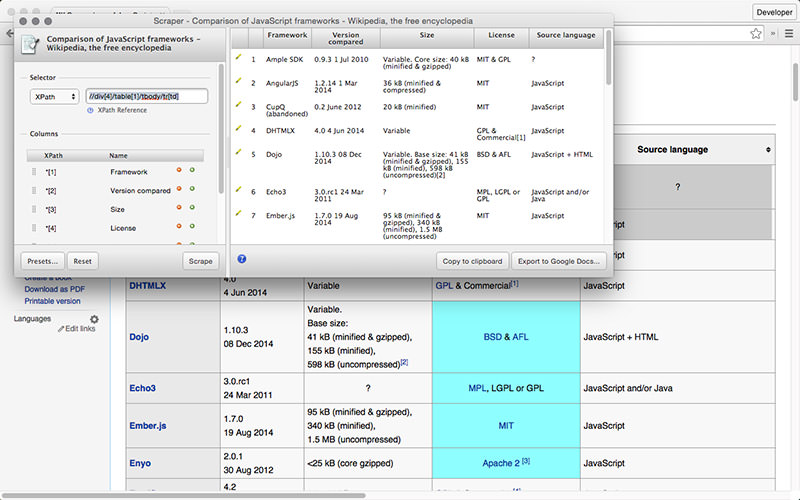
Scraper – a free tool that runs directly in your browser and automatically generates XPaths to define the URLS you want to check. The service is simple, there is no complete automation, or bots, like Import or Webhose, but it can be considered a benefit for beginners because it will not have long to configure to get the desired result.
10. OutWit Hub
OutWit Hub is the Firefox with dozens of functions to retrieve the data. This tool can automatically scan the page and store the extracted information in an appropriate format. OutWit Hub offers a simple interface for retrieving small or large amounts of data as needed.
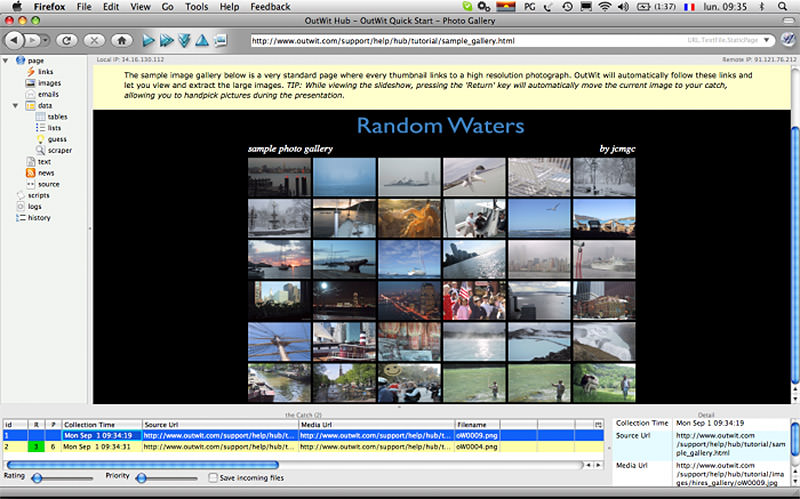
OutWit allows you to "pull" any web page directly from your browser and even create in the panel settings for automatic agents to retrieve the data and save it in the desired format. This is one of the simplest free web tools for data collection, not requiring special knowledge in writing codes.
the
Most importantly, the validity of the parsing?!
Whether a organization to implement automated collection of information posted in open access on sites in a network the Internet (parsing)?
In accordance with applicable Russian Federation law everything is permitted that is not prohibited by law. Parsing is legitimate, in that case, if its implementation do not violate established by the legislation bans. Thus, when the automated collection of information necessary to comply with applicable laws. The legislation of the Russian Federation establishes the following restrictions relating to the Internet
1. Not allowed the violation of Copyright and related rights.
2. Not allowed illegal access to legally protected computer information.
3. Not allowed the collection of information constituting a commercial secret by illegal means.
4. Not allowed deliberately dishonest exercise of civil rights (abuse of right).
5. Not allowed usage of civil rights for the purpose of restricting competition.
Of the above prohibitions, it follows that the organization has the right to exercise the automated collection of information posted on public access sites in the Internet if the following conditions are met:
1. The information is in the public domain and not protected by legislation on copyright and related rights.
2. Automated collection is carried out lawfully.
3. Automated collection of information does not breach the sites in the Internet.
4. Automated collection of information does not lead to restriction of competition.
In compliance with the established restrictions, the Parsing is legal.
p.s. the legal question we have prepared a separate article, which examines the Russian and foreign experience.
What tool to extract the data You like the most? What kind of data you would like to collect? Tell us in the comments about your experience parsing and its vision of a process...


Комментарии
Отправить комментарий