Event bus and data integration in the challenging world of microservices

Valentyn Gogichashvili explains the microservices. Before you is a transcript of the report from Highload++.
Hello, I'm Valentin, Gogichashvili. All the slides I did Latin, I hope. I from Zalando.
What is Zalando? Perhaps you know Lamoda, Zalando was Pope Lamoda their time. To understand what is Zalando, Lamoda need to provide and increase by several times.
Zalando is a store of clothes, we started selling shoes, very nice by the way. Began to expand more and more. From the outside the website looks very simple. For 6 years I worked at Zalando and in 8 years of existence, this company was one of the fastest growing in Europe in some time. Six years ago, when I came to Zalando, she grew up around 100%.
When I started 6 years ago, it was a small startup, I came quite late, there were already 40 people. We started in Berlin for the past 6 years we expanded Zalando Technology for many cities, including Helsinki and Dublin. In Dublin sitting data-is s in Helsinki sit mobile s developer.
Zalando Technology is growing. At the moment we employ around 50 people a month, is a terrible thing. Why? Because we want to build the coolest fashion platform in the world. Very ambitious, let's see what happens.
Want to go back in history and show you the old world in which you, probably, at some point in your career, definitely.
Zalando began as a small service which had 3 levels: web applicaton, backend and database. We used Magento. By the time when I was called at Zalando, we were the biggest users of Magento in the world. We had huge headaches with MySQL.
We started the REBOOT. I came at this project 6 years ago.
the
What we do?
We rewrote everything in Java, because we knew Java. We put PostgreSQL everywhere, because I knew PostgreSQL. Well, Python is a matter of technique. Almost every normal person will back me up that Python tooling'a is the only correct solution (people from the world of Perl, don't kill me). Python is a good joke to write tooling.
We began to develop this scheme:
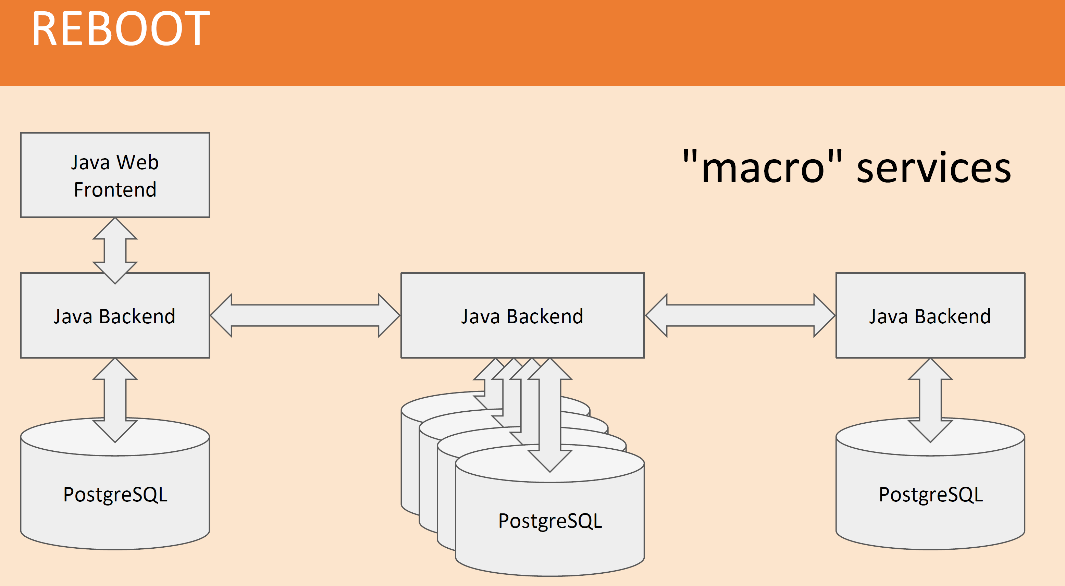
We had a macro system services. Java Backend storage in PostgreSQL c PostgreSQL sharding. I two years ago at the same conference talked about how we make PostgreSQL sharding how we manage schemes as we roll out the version without downtime, it was very interesting.
As I said, Java we all knew. SOAP was used to combine macro-services with each other. PostgreSQL gave us the opportunity to have very clean data. We had a scheme, pure data, transactions, and stored procedures, which we taught all java developer s or those who have left the PHP world we were taught Java and stored procedures.
One hint: if you are in the less than 15 million users a month, you can use the system Java SProc Wrapper to automatically sortirovanie PostgreSQL from Java. A very interesting thing, which PostgreSQL RSP system, essentially.
All was well, we wrote and rewrote everything. We first bought the management system of our warehouses, and then rewrote it all. Because we had to move a lot faster than those people from whom we bought the system could do it.
Everything worked great before the problem with the staff. Our beautiful world began to crumble before our eyes. The standardization system level, which we introduced at the Java level, the SOAP began to crumble. People started to complain and leave, or just not to come.
We told them: you have to write in Java, if you leave, what do we do? If you write something in Haskell or Clojure, and go what do we do? And they replied to us fuck you.
We decided to approach the matter seriously. We decided to rebuild not only the architecture but also the entire organization. We began the process of restructuring of the organization, who have not seen the German industry, in which we said that we completely destroyed everything we had. It was an organization which was around 900 people, we are destroying the hierarchical structure in the form in which it was. We are announcing a Radical Agility.
the
What does it mean?
We declare that we have teams that are Autonomous, which move forward in a meaningful way. Of course we want the people who worked on the case, they did this with skill.
Offline command.
They can choose their own technology stack. If the team decided that they would write in Haskell or Clojure, then so be it. But you have to pay. Teams must maintain the services that they wrote themselves, to Wake up in the night yourself. Including the selection of persistent stack. We taught PostgreSQL, if you want to choose MongoDB and no stop MongoDB are blocked. We have radar technology in which we conduct monthly surveys and technology that we consider dangerous, we put on the red sector. This means that the team can choose those technologies, but they are to blame entirely on yourself if something goes wrong.
We said that the team will isolate their AWS accounts. Before that we were in their own data centers, selecting AWS, we made a deal with the devil. We said, we know that it will cost more, but we will move faster. We will not have situations like that, in their own data centers in order to arrange a single hard drive, it required 6 weeks. It was unbearable and impossible. We could not move forward.
Many people believe that autonomy is anarchy. Autonomy is not anarchy. With autonomy comes a lot of responsibility, especially for Zalando, which is a publicly traded company. We at the exchange and in any publicly traded company, we come to the auditors and they check how our system. We had to create some kind of structure that will allow our developer am to work with AWS, but still be able to answer auditors ' questions of: "Why you have this IP address in the public domain without any identification?"
Got this system:

We wanted to make it as simple as possible, it is really simple. But I swear, when you see it.
If you go to AWS, reminding you, with this speed and openness, and if you choose the idea of microservices or public services, for it may have to pay. Including if you want to make a system that is safe, which answers the questions that you can ask our auditors.
Of course we said that in order to support heterogeneous stack of technologies we raise the level of standardization with Java and PostgreSQL at a higher level. We raise the level of standardization on the level of REST APIs.
What does it mean? I mentioned this in the previous report that we need a system for describing the API. System description the microservices communicate with each other. We need the order. On some level we need to standardize. We have announced that we will have a API system first. And that every service before you start to write, the team should come to the Guild API, and to persuade them to take part API approved API. We wrote a REST API guidelines, very interesting. They even referred to some resources. First API library that allow you to use Swagger (OpenAPI) as rotorob for the server. For example, connection is a rutor to flask'a Python, and play-swagger — is a rutor to play system in Scala. For Clojure there is the same rutor, it is very convenient. You write first, the Swagger file, describe what you want to achieve from your micro service, and then just indicate which functions your system must perform certain operations in the API.
But the problem with microservices. I want to repeat several times the phrase. The microservices are the answer to organizational problems, this is not a technical answer. I would not advise the microservices anyone who small. I would not advise the microservices those who have no problems with heterogeneous technological basis who do not need to write a service in Scala, another service in Python or Haskell. A number of problems with microservices is quite high. This barrier. In order to overcome it, you need quite a lot of pain to experience before it, as did we.
One of the biggest problems with miraservice: microservices by its very definition denies access to the system persistence data. Base hidden inside the micro service.
So classic extract transform load process is not running.
Let's make one step back and remember how to operate in the classical world. What do we have? We have a classical world, we have developer s junior developer s senior s developer, DBA and Business Intelligence.
the
How it works?
In a simple case, we have business logic, database, ETL process pulls directly from the database of our data and puts in the Date Warehouse (DWH).
On a larger scale we have many services, many bases and one process that is likely to handles. Pull data from these databases and placed into a special database for the business analysts. It is very well structured, business analysts understand what they are doing.
Of course this is not without problems. It's all very difficult to automate. In the world of microservices we are all wrong.
When we announced the microservices when we announced the Radical Agility, when we announced all these wonderful innovations for developer'ov, business analysts were very unhappy.
How to gather data from a huge number of the microservices?
We are not talking about tens and hundreds or even thousands. Then comes Valentine on the horse and says: we all will write in the thread queue. Then the architects say: why queue? Someone will use Kafka, someone would use a Rabbit as we will it all integrate? Our security officer s said, never in my life, we will not allow. Our business analysts said, if there is no scheme, we will be saved and will not be able to understand what is flowing, it will be just a gutter and not a transportation system data.
We sat down and began to confer and decide what to do. Our main goals are: ease of use of our system, we want, we don't have single point of failure, it was not such a monster that if it falls, all will fall. Must be a secure system, and this system should satisfy the needs of the business intelligence system should satisfy our data-is ov. It should be a good event to allow other services to use the data that flow across the tire.
Very simple. Event Bus.
From Event Bus we can get Business Intelligence or in some Data heavy services. DDDM is a favorite concept lately. This is the data driven decisions making system. Any Manager will be delighted with this word. Machine learning and DDDM.
the
What we came up with?
Nakadi. You probably realized that I have a name quite Georgian. Nakadi in Georgian means flow. For example, mountain stream.
We started to make this thread. The basic principles that we have invested a little again.
We said that we would have a standard HTTP API. Possible — restful. We do centralized and not very centralized event type registry. We introduce different classes of event types. For example, at the moment, we have supported two classes. This data capture and business events. That is, if we change the essence, we can capture the event record with all the necessary meta-information. If we have just the information that the business process something happened, it is usually a much more simple case, we can write a more simple event. Still, the business intelligence require us to have organized structure, which can automatically parse.
Having vast experience with PostgreSQL and with the schemes, we know that without the support of versioning schemes nothing will work. That is, if we sink to the level where the programmers will have to describe the order created, order created then 1,2,3, we will, in essence, making the system similar to Microsoft Windows and it will be very difficult, especially in order to understand how to develop personality, how versionrelease essence. It is very important that this interface allow data to stream to be able to respond as quickly as possible to messages and alert everyone about the arrival of a message.
We didn't want to reinvent the wheel. Our goal is to make as minimal a system that will use existing systems. So at this point we took Kafk', as underline the system and PostgreSQL to store metadata and schema.
Nakadi Cluster is what we have. Exists in the form of open source project. At the moment, it validates the scheme, which were registered before. He is able to record additional information in the event of metapola for a. For example, the time of arrival or if the client did not create a unique id for the event a, and a unique id you can put.
We also felt that we need to take control of offset of AMI. Those who know how to work Kafka. Does anyone know? Good, but not most. Kafka is a classic pub/sub system in which the producer writes data sequentially, and the client does not store as classic message.....
For the client does not create a separate copy of the message, the only thing the client is offset. That is, the shift in this endless thread. I can imagine that Kafka is such an endless stream of data in which each line is numbered. If your customer wants data, he says, read from the position X. Kafka will give him the data from the position X. Thus, we guarantee the orderliness of the data, this ensures that the server does not need to store a lot of information, as is usually done in a classic message systems that allow you to komitite part of a read event'ov. In this situation, we have a problem that cannot be zammitti piece of the read block. Now went offtext about Kafk'y didn't want to say, sorry.
High level interface makes reading from kafk'and very easy for customers. Customers should not share information from what section he reads, what offset s they keep the. Just a client comes and gets what you need from the system. We decided to go the way of minimal resistance. Zookeeper is already for Kafk'and what would be a terrible Zookeeper was, he we already have, we already need manage'it and we use it to store the offset s and the additional information. PostgreSQL for metadata and storage schemes.
Now I want to tell in what direction we are moving.
We are moving very quickly. So when I return to Berlin, some parts are already done.
At the moment we have a Cluster Nakadi, Nakadi we have UI, we started writing for the Elm to interest other people. Elm is cool, love it.
The next step we want to be able to manage multiple clusters. We have seen the shoals, when a new producer and starts to write 10 s of thousands of event per second, not warning about anything.
Our cluster does not have time to scale. We want to have different clusters for different data types. Standardization of the interface we did specifically so that there was no drawstring Kafk'y.
We can switch from Kafk'and Redis. And Redis'a Kinesis. Essentially, the idea is that depending on the need of the service and properties of the event s, they write, if someone is not interested ordering, orderliness, you can use a system that does not support the ordering and more effective than Kafka. At the moment we have the opportunity to abstract it using our interface.
Nakadi Scheme Manager to pull out of a cluster because it needs to be sasaran. The next step is this idea that we have the schema are detected. That is, increases micro service, publiceret your swagger file publiceret a list of event s in the same format as swagger. Automatically crawker takes it all and saves the developer from s need before deployment'om inject'it the schema in the message bus.
And of course, the topology manager in order somehow to routit producer and consumerb on different clusters. Then told me that Kafka is running as an elephant. No, not an elephant and like a locomotive. In our situation this locomotive breaks down all the time. Don't know who produced this locomotive, but in order to manage Kafk'Oh in the AWS, it turned out that it's not easy.
We wrote a system Bubuku, a very good name, very Russian.
What makes Bubuku?
I had a big slide that listed what makes Bubuku, but he was very big. All you can see on the link.
In the trailer Bubuku has goals to do something that other people do not, with Kafk'Oh. The main ideas that automatically reportition, automatic scaling and the ability to survive being hit by lightning, crazy monkeys that kill instances.
By the way, system testing, Chaos Monkey, and very well it works. I recommend, if you write microservices, always think how the system is going through a Chaos Monkey. It — Netflix is a system which randomly kills nodes or disables the network spoils system
What would you the system is not built, if you don't test, it won't work if something is broken.
Concluding its surface story, I want to say: what I told, now we are in open source. Why open source? We have even written, why Zalando makes open source.
When people write open source, they write not for the company but for themselves partly. So we see that the quality of products is better, we see that izoliruemogo products from the infrastructure better. There are no records inside zalando.de not rule the keys, not comitat in Git.
We have principles about how open source it. Do you have questions in the company should we open source it or not? Is the principle open source first. Before you start a project, we think, is it worth it open source it. In order to understand and answer this question we need to answer the questions:
the
-
the
- Who cares? the
- do we care? the
- do we Want this to do, as an open source project? the
- that we will keep this in publice tree?
There are things that I don't have open source:
the
-
the
- If your project contains domain knowledge, which makes your company, it is not open source it, of course.
This is the last slide here projects that were mentioned today:

If you go to zalando.github.io, there is a huge number of projects on PostgreSQL, a lot of libraries, both for backend and frontend, I highly recommend.
I ran out of time.
the Report: Event bus and data integration in the challenging world of microservices


Комментарии
Отправить комментарий